어시스트핏의 Observability 시스템 구축기

SSH 로그 확인에서 벗어나기까지
시작에 앞서
안녕하세요! 에이피티플레이(APTPLAY)에서 서버 개발을 담당하고 있는 고현석 입니다🫡
서비스가 안정적으로 운영되기 위해서는 단순히 "잘 돌아가는 것처럼 보이는 것"이 아니라, 지표를 기반으로 시스템의 상태를 실시간으로 관찰하고 문제를 빠르게 감지할 수 있어야 합니다. 특히, 트래픽이 증가하거나 외부 연동이 많아지는 복잡한 환경에서는 “어떤 요청이 느려졌는가?”, “장애 조짐이 보이는가?”, “어디서 병목이 발생했는가?”와 같은 질문에 수치로 답변할 수 있어야 운영 리스크를 줄일 수 있습니다.
어시스트핏은 출시한지 1년이 다 되어가지만, 다른 업무에 우선순위가 밀려 아직 제대로 된 옵저버빌리티 시스템이 없었습니다. 트래픽이 높지 않았기에 이슈가 발생하지 않았고, 장애 시 ssh 접속을 통해 로그를 확인했죠. 하지만 시간이 지나면서 고객 센터들이 점차 늘어났고, 2025년 3월, 스포엑스(SPOEX) 행사를 기점으로 가파른 성장을 기대하게 되면서 안정적인 서비스 운영과 장애 대응 프로세스 개선을 위해 옵저버빌리티 시스템 구축을 제안하게 되었습니다.
따라서 이번 글에서는 어시스트핏(Assistfit) 서비스 서버의 옵저버빌리티 시스템 구축 과정을 소개해보려 합니다.
Monitoring? Observability?
옵저버빌리티(observability)? 다들 모니터링(monitoring)이라는 단어는 많이
들어보셨을텐데요, 모니터링은 시스템의 CPU 사용량, 메모리 사용량, 네트워크 트래픽
등의 데이터를 수집하고 분석하여 성능과 동작을 파악하는 도구 입니다. 우리는
모니터링을 통해 사전에 정의된 메트릭(Metric)을 수집하고, 임계치(Threshold)를
기반으로 알람을 설정할 수 있습니다. 즉, 모니터링을 한 마디로 정리하면
정의된 문제가 발생했는지 감시하는 행위 입니다.
하지만 모니터링은 만능이 아닙니다. 비즈니스가 점점 복잡해지고 서비스가 커져가면서 여러 가지 이유로 모놀리스(Monolith)의 단점을 지적하고, 매크로서비스(Macroservices) 혹은 마이크로서비스(Microservices)를 채택하고 있습니다. 이러한 환경에서 모니터링은 특정 유형의 문제를 감지하는 데 효과적이지만, IT 시스템 동작을 전체적으로 파악하거나 근본 원인 분석에 대한 심층적인 인사이트는 제한적일 수 있습니다. 또, 이를 직접 디버깅 하는 것은 쉽지 않을 것입니다.
그렇게 등장한 옵저버빌리티는 시스템 내부 상태를 밖에서 이해할 수 있게
만드는 능력을 가지고 있습니다. 옵저버빌리티의 목적은 모니터링의 기능을 넘어 발생
가능한 모든 오류에 대한 근본 원인을 파악하는 것입니다. 다음은 복잡한 시스템에서
옵저버빌리티를 통해 취할 수 있는 이점들 입니다.
- 복잡한 시스템에서 발생하는 문제 빠르게 파악 가능
- 전체 시스템의 내부 동작을 쉽게 이해 가능
- 대규모 분산 시스템에서 서버, 네트워크 등에서 발생하는 다양한 데이터를 수집 및 분석
- 시스템의 성능을 지속적으로 모니터링 및 문제 예방
Observability의 구성 요소
그렇다면 우리는 Observability 시스템을 어떻게 구축할 수 있을까요?
| 구성 | 목적 | 설명 | 주요 특성 |
|---|---|---|---|
| Metrics | 시스템 상태를 수치로 지속적으로 측정 | CPU 사용률, 요청 수, DB 연결 수처럼 시간 단위로 집계된 데이터 | 📈 Aggregatable → 시계열 데이터 기반으로 평균, 최대, 합계 등 수학적으로 집계 가능 |
| Traces | 하나의 요청이 시스템을 거치는 흐름 추적 | 분산 환경에서 요청이 여러 서비스를 거칠 때 흐름을 시각화 | 🧭 Request scoped → Trace Context를 기반으로 하나의 요청 단위 전파 및 Trace ID, Span ID |
| Logs | 이벤트나 예외의 발생 맥락 기록 | 에러 메시지, 상태 변경, 비즈니스 이벤트 등 텍스트 기반 로그 메시지 | 📜 Event-based → 애플리케이션의 Event를 기록하여 시점별 단편적, 맥락 분석 시 유용 |
이 세 요소는 서로 다른 책임을 가지고 있, 각 요소들은 서로 상관관계를 가지고 있습니다. 아래 사진은 Grafana 공식문서에서 발췌한 옵저버빌리티 데이터의 상호작용 입니다.
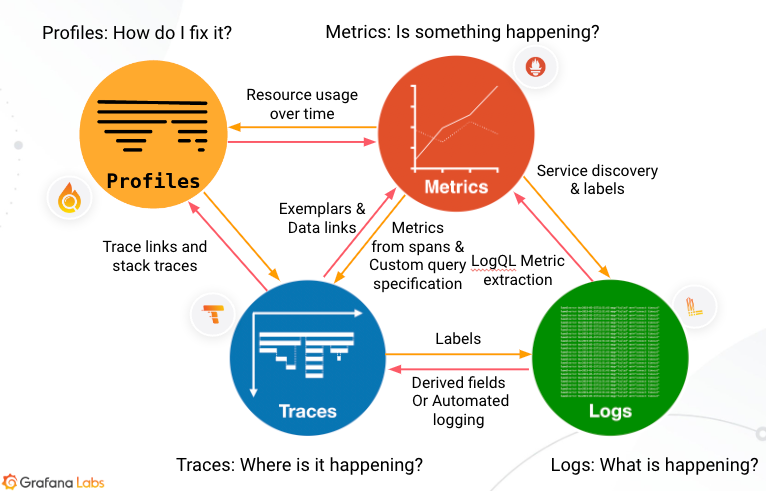
Metrics ↔ Traces
메트릭에서 이상이 감지되면 Exemplar를 통해 해당 요청의 Trace로 이동할
수 있습니다. 반대로, Trace에서 각 요청의 latency, error 비율 등을
Span 기반 메트릭으로 변환할 수 있습니다.
Metrics ↔ Logs
Prometheus의 메트릭 라벨을 활용하여, Loki 로그를 빠르게 필터링할 수
있습니다. LogQL을 사용하면 로그로부터 메트릭을 추출하여 알람이나 시각화에
활용할 수 있습니다.
Traces ↔ Logs
로그 안에 trace_id가 포함되어 있으면 해당 요청의 트레이스를 쉽게 추적할
수 있습니다. Trace에서 연관된 로그 라벨로 필터링해 문맥 파악이 가능합니다.
Observability 시스템 구축기
지금부터 위에서 살펴본대로 메트릭, 트레이스, 로그를 수집할 수 있는 옵저버빌리티 시스템을 구축해 보겠습니다.
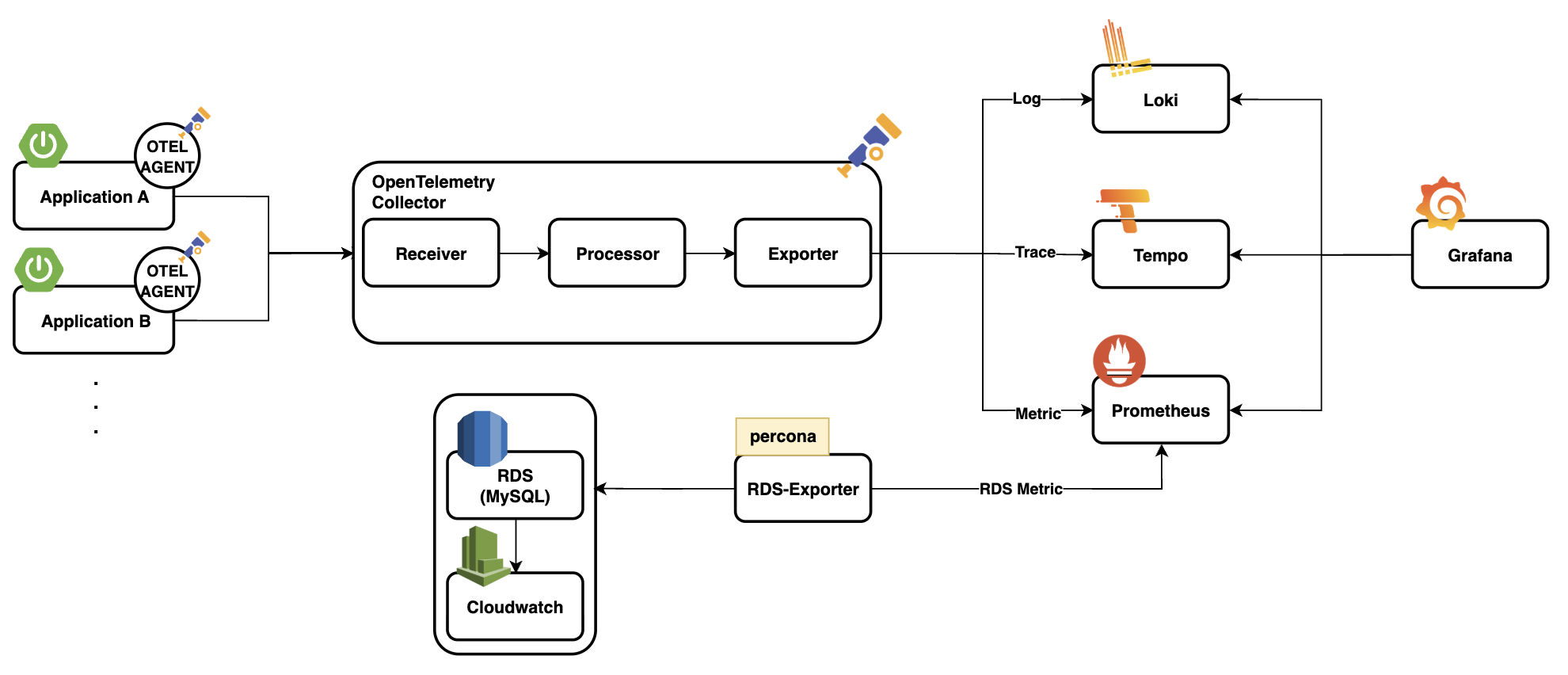
시스템은 크게 두 가지 데이터 흐름으로 구성됩니다:
- Application Layer에서 수집되는 Trace / Log / Metric
- Database(RDS) Layer에서 수집되는 Metric
두 경로의 데이터는 공통적으로 Grafana를 통해 시각화되며, Prometheus, Tempo, Loki가 각각 메트릭, 트레이스, 로그 저장소 역할을 합니다. 중앙에는 OpenTelemetry Collector가 위치하여 다양한 데이터를 수집하고 목적에 따라 export 합니다.
RDS의 경우, RDS Exporter를 활용하여 CloudWatch로부터 메트릭을 주기적으로 수집합니다. 이 데이터들을 Prometheus가 주기적으로 Scrape 하여 저장합니다.
OpenTelemetry 도입기
OpenTelemetry(OTel)는 로그, 메트릭, 트레이스와 같은 관측 데이터를 수집하고 전송하는 공통 표준입니다. 우리는 관측 데이터의 수집 방식과 형식을 표준화하고, 이후의 처리 및 저장은 다양한 오픈소스 도구에 유연하게 연결하고자 OTel을 선택했습니다.
OTel과 Spring Boot 3.x와의 합도 굉장히 좋은데요, Spring Boot 3.x는 Micrometer Tracing 및 Micrometer Observation을 통해 OpenTelemetry와의 통합을 사실상 기본 기능으로 내장하고 있습니다. 이를 통해 복잡한 설정 없이, @Observed나 actuator 기반으로 trace와 metric을 수집할 수 있습니다. 다음은 Spring Boot 릴리스 노트에서 언급된 내용입니다.
📌 Spring Boot 3.0 Release Notes
Spring Boot now auto-configures Micrometer Tracing for you. This includes support for Brave, OpenTelemetry, Zipkin and Wavefront.
📌 Spring Boot 3.1 Release Notes
When io.opentelemetry:opentelemetry-exporter-otlp is on the classpath, an OtlpHttpSpanExporter will be auto-configured.
저희는 Spring Boot 3.1.4 버전을 활용하고 있고, 3.x 버전에서 제공하는
기능들을 적극 활용할 수 있는 상황이었지만, 옵저버빌리티 시스템의 빠른 도입을
위해 우선 javaagent를 활용하기로 하였습니다.
먼저, OpenTelemetry SDK 1.47.0 버전을 활용하기 위해 open-telemetry/opentelemetry-java-instrumentation 2.13.0 버전 javaagent.jar 파일을 다운로드 하였습니다. javaagent를 애플리케이션에 붙일 때는 다음과 같이 실행할 수 있습니다.
java \
-javaagent:./opentelemetry-javaagent.jar \
-Dotel.service.name=$SERVICE_NAME \
-Dotel.exporter.otlp.endpoint=http://$COLLECTOR_IP:4317 \
-Dotel.exporter.otlp.protocol=grpc \
-Dotel.instrumentation.micrometer.enabled=true \
-Dspring.profiles.active="$SPRING_ACTIVE_PROFILES" \
-jar application.jar
애플리케이션에 Java Agent를 붙였으니 이제 Collector 설정을 해주어야 합니다. Collector의 경우, gRPC 프로토콜에 대하여 수신 가능하게 설정하였습니다. gRPC의 경우, 바이너리 전송, keep-alive 등을 통해 HTTP에 비해 고성능을 보장해줍니다. 추가적으로 얼마의 주기로 얼마의 일정량을 묶어서 처리할지 설정해주었습니다.
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
processors:
batch:
send_batch_max_size: 1000
send_batch_size: 100
timeout: 10s
exporters:
prometheusremotewrite:
endpoint: 'http://prometheus:9090/api/v1/write'
otlp/tempo:
endpoint: 'http://tempo:4317'
tls:
insecure: true
loki:
endpoint: 'http://loki:3100/loki/api/v1/push'
service:
pipelines:
metrics:
receivers: [otlp]
processors: [batch]
exporters: [prometheusremotewrite]
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp/tempo]
logs:
receivers: [otlp]
processors: [batch]
exporters: [loki]
service에는 메트릭, 트레이스, 로그 데이터를 각각 Prometheus, Tempo, Loki에 전송할 수 있도록 설정해주었습니다. 이처럼 Otel Collector는 Exporter 역할도 해줍니다.
Prometheus로 메트릭 수집하기
메트릭 수집을 담당하는 Prometheus는 OTel Collector와 RDS Exporter로부터
메트릭을 스크래핑 해옵니다. 따라서 scrape_configs에 해당 설정을 해주었습니다
. . .
scrape_configs:
- job_name: otel_collector
. . .
static_configs:
- targets:
- collector:8889
- job_name: rds-exporter
. . .
static_configs:
- targets:
- rds_exporter:9042
Tempo로 Trace 데이터 저장하기
Tempo는 분산 트레이싱 시스템으로, OpenTelemetry 등에서 받은 trace 데이터를 저장하고 Grafana에서 조회할 수 있게 해줍니다.
server:
http_listen_port: 3200
distributor:
receivers:
otlp:
protocols:
http: {}
grpc:
endpoint: 0.0.0.0:4317
opencensus:
. . .
metrics_generator:
registry:
external_labels:
source: tempo
cluster: docker-compose
storage:
path: /tmp/tempo/generator/wal
remote_write:
- url: http://prometheus:9090/api/v1/write
send_exemplars: true
storage:
trace:
backend: local
wal:
path: /tmp/tempo/wal
local:
path: /tmp/tempo/blocks
overrides:
metrics_generator_processors: [service-graphs, span-metrics]
설정에서 중요시 봐야할 부분은 먼저 metrics_generator 입니다. trace를
기반으로 metrics를 생성할 수 있는 기능에 대한 설정으로, 글의 초반부에서
말씀드렸던 trace_id 기반 exemplar를 지원하도록 설정해주었습니다.
storage 설정을 통해 실제 trace 데이터 저장에 대한 설정을 할 수 있는데요, 운영 환경에서는 s3 등의 분산 스토리지에 저장해야 합니다.
metrics_generator_processors은 어떤 타입의 metric을 생성할지에 대한
설정입니다. 여기에 local-blocks 설정을 추가해주면 Grafana의 Drilldown 기능을
활용할 수 있습니다.
Loki로 로그 수집 및 연동하기
https://opentelemetry.io/docs/specs/otel/logs
OpenTelemetry defines a Logs API for emitting LogRecords. It is provided for library authors to build log appender, which use the API to bridge between existing logging libraries and the OpenTelemetry log data model.
Loki와 관련된 레퍼런스를 찾아보시면 local-config.yml을 활용하는 예제가
많을텐데요, local-config.yml 설정은 데이터 영속성이 없기 때문에 로컬 환경이나
개발 환경에 적합합니다. 아래는 운영 환경에 활용할 수 있는 예시 입니다.
server:
http_listen_port: 3100
grpc_listen_port: 9095
. . .
storage_config:
boltdb_shipper:
active_index_directory: /loki/index
cache_location: /loki/index_cache
shared_store: s3
aws:
s3: s3://<ACCESS_KEY>:<SECRET_KEY>@<BUCKET_NAME>/<PREFIX>
region: ap-northeast-2
s3forcepathstyle: true
compactor:
working_directory: /loki/compactor
shared_store: s3
compaction_interval: 5m
limits_config:
retention_period: 168h
로그 데이터를 S3에 저장하도록 설정해주었습니다.
저희는 옵저버빌리티 시스템을 먼저 구축하고, 추후에 로그 저장 정책을 수립하기로 결정하여 일단 local-config를 활용하였습니다. 추가로 어떻게 Log를 쌓아야 장애 대응 프로세스에 이점을 극대화 할 수 있을지 논의 중에 있습니다.
RDS Exporter
RDS의 메트릭을 추출할 때 OS 관련 메트릭을 추출하기 위해 node_exporter를, DB 관련 메트릭을 추출하기 위해 mysqld_exporter를 활용할 수 있는데요, 두 메트릭을 모두 추출하기 위해선 rds_exporter를 활용해야 합니다. rds_exporter 오픈소스로는 두 가지가 있었습니다.
- percona/rds_exporter
- [qonto/prometheus-rds-exporter](https://github.com/qonto/ prometheus-rds-exporter?tab=readme-ov-file)
qonto/prometheus-rds-exporter로 구축해보았을 떄, 대시보드를
제공해주어서 편하게 활용할 수 있었으나, Select Latency, Commit Latency, DeadLock
발생횟수 등을 가져오지 못합니다. percona/rds_exporter는 basic에서부터 다양한
데이터를 가져오고, enhanced 기능을 활용하면 RDS 인스턴스 내부의 OS 메트릭까지
수집할 수 있습니다. 따라서 qonto/prometheus-rds-exporter를 내리고
percona/rds_exporter로 활용하게 되었습니다.
Grafana를 통한 통합 대시보드 구성
Grafana란, Grafana Labs 에서 관리하고 있는 오픈 소스 시각화 및 분석 도구입니다. Grafana를 통해 수집한 메트릭, 트레이스, 로그 데이터를 대시보드를 통해 시각화 할 수 있습니다. 다음은 Grafana의 datasource.yml의 일부분 입니다.
. . .
datasources:
- name: Prometheus
type: prometheus
uid: prometheus
access: proxy
url: http://prometheus:9090
jsonData:
exemplarTraceIdDestinations:
- datasourceUid: tempo
name: trace_id
. . .
Prometheus에서 수집한 메트릭에 trace ID가 포함된 exemplar가 존재할 경우, Grafana는 해당 trace_id를 기반으로 Tempo에 직접 연결할 수 있습니다.
- name: Loki
type: loki
uid: loki
access: proxy
url: http://loki:3100
jsonData:
derivedFields:
- datasourceUid: tempo
matcherRegex: '"traceid":"(\w+)"'
url: '$${__value.raw}'
name: traceId
. . .
Loki 로그 내에 matcherRegex 정규식에 해당하는 문제열이 포함돼 있다면,
Grafana는 정규식을 통해 trace ID를 추출하고 Tempo와 연동합니다.
- name: Tempo
type: tempo
uid: tempo
access: proxy
url: http://tempo:3200
jsonData:
tracesToMetrics:
datasourceUid: prometheus
tags: [ { key: 'service.name', value: 'job' }, { key: 'method' }, { key: 'uri' }, { key: 'outcome' }, { key: 'status' }, { key: 'exception' } ]
queries:
- name: 'Requests'
query: 'sum(rate(http_server_requests_seconds_count{$$__tags}[10m]))'
tracesToLogsV2:
datasourceUid: loki
filterByTraceID: true
filterBySpanID: true
. . .
Tempo에서 선택한 트레이스에 포함된 tag들을 기준으로, 자동으로 관련 메트릭 쿼리를 생성해 Prometheus로부터 지표를 시각화합니다.
docker-compose로 전체 시스템 실행하기
이제 지금까지 설정한 config 파일을 활용하여 docker-compose를 통해 한번에 실행해 봅시다.
version: '3.8'
services:
collector:
container_name: collector
image: otel/opentelemetry-collector-contrib:0.123.0
. . .
restart: always
ports:
- '4317:4317'
- '4318:4318'
- '8888:8888'
- '8889:8889'
depends_on:
- loki
- tempo
tempo:
container_name: tempo
image: grafana/tempo:latest
. . .
restart: always
ports:
- '4317'
- '3200'
loki:
container_name: loki
image: grafana/loki:latest
. . .
restart: always
ports:
- '3100'
prometheus:
container_name: prometheus
image: prom/prometheus
. . .
restart: always
user: root
ports:
- '9090:9090'
depends_on:
- collector
rds_exporter:
container_name: rds_exporter
. . .
ports:
- "9042:9042"
restart: unless-stopped
depends_on:
- prometheus
grafana:
container_name: grafana
image: grafana/grafana
volumes: . . .
restart: unless-stopped
ports:
- '3000:3000'
user: root
depends_on:
- prometheus
- loki
- tempo
마무리하며
지금까지 구성한 옵저버빌리티 시스템을 바탕으로 대시보드를 구성해보았습니다.
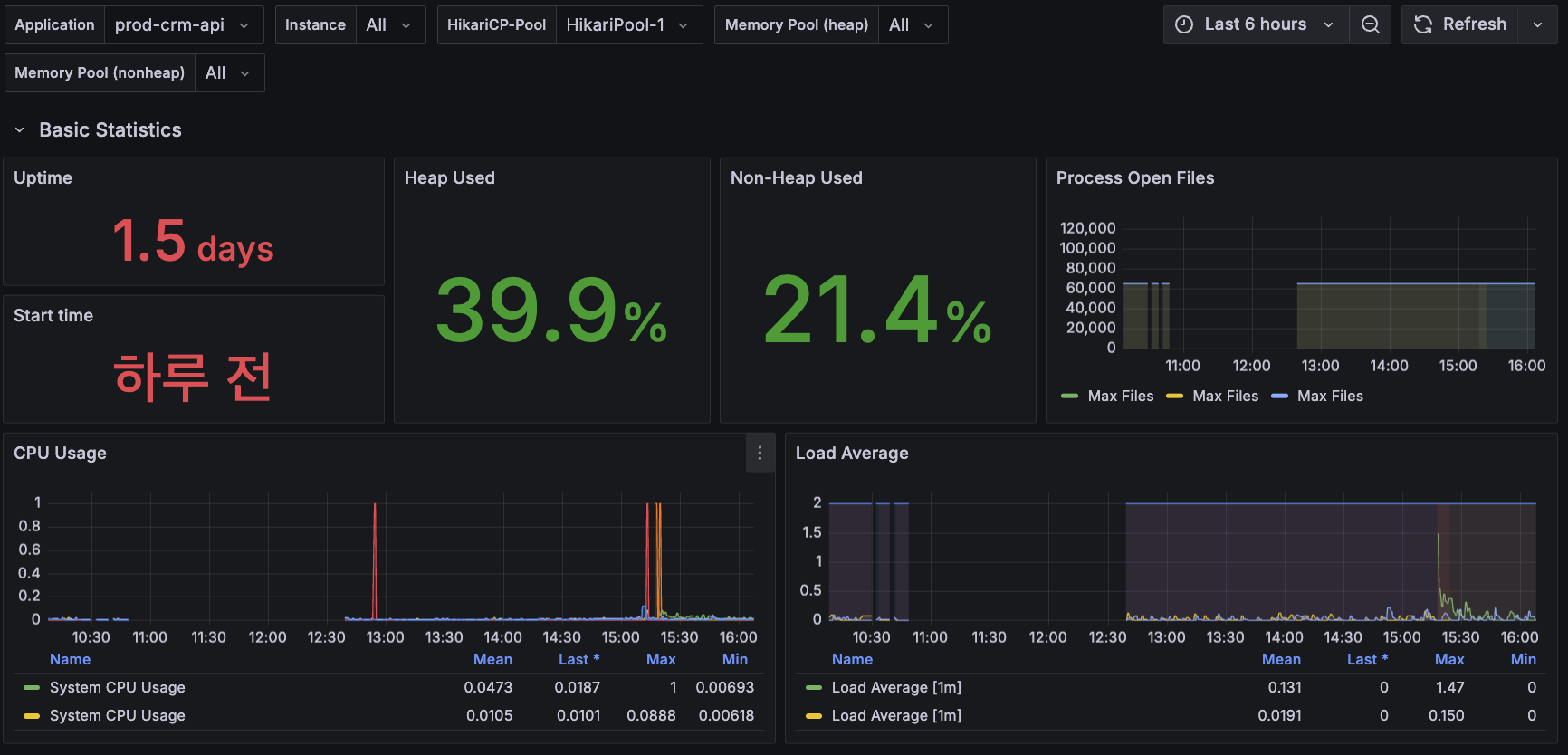
(Spring 애플리케이션에 대한 대시보드의 일부)
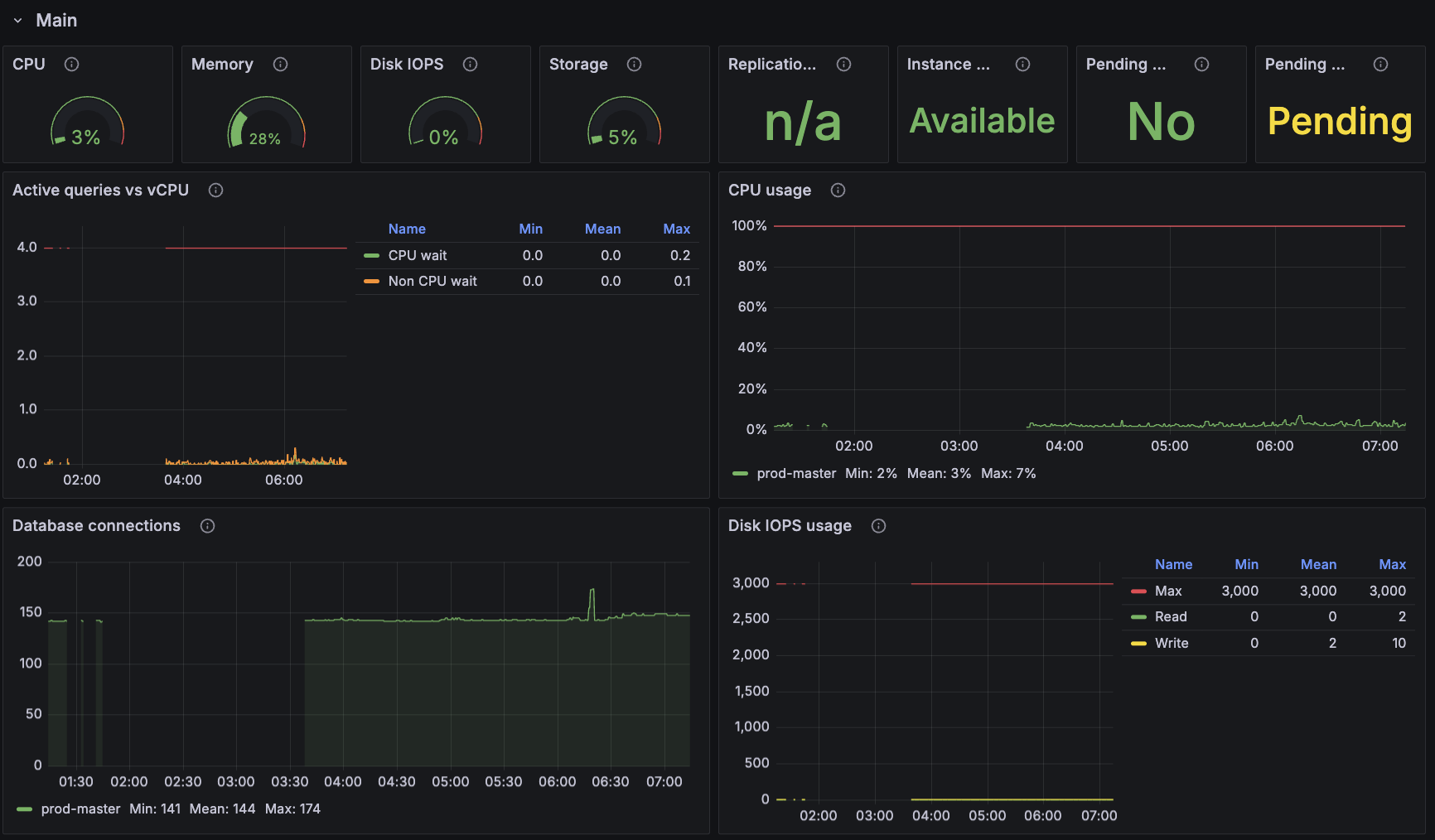
(RDS에 대한 대시보드의 일부)
이번 포스팅에서는 OpenTelemetry를 중심으로 Prometheus, Tempo, Loki를 연동하여 Metrics → Traces → Logs가 유기적으로 연결된 옵저버빌리티 시스템을 구축해보았습니다. 단일 지표나 로그에 의존하던 기존 방식에서 벗어나, 이상 징후를 감지하고 원인을 추적하는 전 과정을 하나의 흐름으로 통합함으로써, 장애 대응 시간은 줄이고 시스템 신뢰도는 높일 수 있게 되었습니다.
물론 여기서 다룬 구성은 시작일 뿐입니다. 운영 환경에 맞는 보안 설정, 스토리지 최적화, Alert Manager를 통한 알람 구성 등을 더한다면 더욱 강력한 관측 시스템으로 발전시킬 수 있습니다. 옵저버빌리티 시스템을 고도화 하면서 추가로 공유드릴 내용이 있다면 2탄으로 찾아뵙겠습니다.
긴 글 읽어주셔서 감사합니다. 🙇♂️