Clean DDD를 위해 JPA와 이별하기

JPA 없어도 괜찮아 딩딩딩딩딩 🎶
시작에 앞서
안녕하세요! 에이피티플레이(APTPLAY)에서 서버 개발을 담당하고 있는 고현석 입니다🫡
여러분들은 Big Ball of Mud에 대해 들어보셨나요? Big Ball of Mud는 특정한 구조없이 성장한 시스템을 설명하는 소프트웨어 아키텍처 패턴을 말합니다. 시간적 압박, 요구 사항의 변화 등이 Big Ball of Mud의 주 원인이 됩니다. 엉망진창 아키텍처라는 설명과 역설되게, 이 패턴은 작은 소프트웨어의 경우에서 빠른 생산성 등의 장점을 가지고 있습니다.
2024년 7월, 전국 피트니스 센터를 대상으로 한 CRM 서비스인 어시스트핏이 출시되었습니다. 그리고 제품이 출시와 여러 릴리스를 거치면서 프로젝트 몸집은 점점 커지고, 기존 코드와 구조들이 Big Ball of Mud 상태임을 인지하였습니다. 이후 DDD를 적용하는 리팩토링에 대해 팀에 제안하게 되었고, 2024년 12월부터 본격적으로 프로젝트를 시작하게 되었습니다.
현재는 리팩토링 된 출석 서버를 QA를 거쳐 운영 환경에 배포한 상황이고, CRM 서버도 빠르게 작업하고 있습니다. 도메인 추출, 이벤트 스토밍 등 전략적 설계부터 애그리거트(Aggregate) 패턴, 애플리케이션 아키텍처 등 전술적 설계까지 풀어낼 이야기가 정말 많지만, 이번 포스팅에서는 Clean DDD를 위해 JPA의 편리한 기능들과 이별한 이야기를 하려고 합니다...⭐️
JPA Entity와 도메인 Entity를 분리해야 하는가?
Spring Boot를 기반으로 개발하는 팀에서 도메인 주도 설계를 할 때, 화두에 자주 오르는 주제가 있는데, 바로 JPA 엔티티와 도메인 엔티티를 분리해야 하는가 입니다. 이를 논하기 전에 도메인과 관련된 몇 가지 용어와 설명을 적어보았습니다.
도메인이 도대체 뭔데?
- 도메인: 소프트웨어로 해결하고자 하는 문제 영역
- 도메인 지식: 도메인에 대한 깊은 이해와 경험
- 도메인 모델: 도메인을 소프트웨어적으로 표현한 모델
- 엔티티: 도메인 모델을 구성하는 객체 중 하나
DDD에서는 도메인이라는 문제 영역을 해결하기 위해 도메인 지식과 유비쿼터스 언어를 기반으로 도메인 모델을 정의하고, 이를 코드로 구현합니다. 도메인 모델은 애그리거트(Aggregate), 엔티티(Entity), 값 객체(Value Object) 등으로 구성되는데, 여기서 말하는 엔티티가 바로 도메인 엔티티 입니다.
AS-IS 프로젝트에서는 비즈니스 요구사항을 분석하고 설계한 이후, 이를 코드로 구현하는 과정에서 비즈니스 모델과 실제 코드가 불일치하는 문제가 발생했습니다. 시스템은 도메인을 가장 잘 표현해야 하는데, 설계 모델에서 코드로 변환하는 과정에서 기술 언어로 오염되었기 때문입니다.
도메인 모델에서 코드로 구현 과정
도메인 주도 설계를 적용하면 이러한 문제 및 고민거리가 해소됩니다. DDD에서는 설계 모델을 코드로 변환하는 기존 방식과 다르게 유비쿼터스 언어로 도메인 모델을 설계하고, 그 도메인 모델을 그대로 코드 레벨로 투영시킵니다. 이를 통해 도메인 로직이 엔티티와 도메인 서비스에 명확하게 분리되어 서비스 계층이 단순한 트랜잭션 스크립트에서 벗어나, 도메인 로직을 중심으로 정리되고, 설계가 변경되는 경우에도 코드에 자연스럽게 반영되기 때문에 유지보수성과 확장성이 향상된다는 이점을 취할 수 있습니다.
그런데 본격적으로 코드로 리팩토링 하기 위해 스켈레톤 코드를 작성하면서 한 가지 고민거리가 생겼습니다. JPA 엔티티와 도메인 엔티티를 통합할지, 분리할지 입니다. 또, 그 이전에 두 개념이 동일한 것인가에 대해 생각해 보았습니다.
JPA 엔티티 ≠ 도메인 엔티티
해당 문제를 바라보는 관점과 생각은 여러 가지가 있겠지만, 저는 JPA 엔티티와 도메인 엔티티는 본질적으로는 다르다고 생각합니다. 도메인 엔티티는 도메인의 핵심 개념을 표현하며, 비즈니스 로직을 포함하는 객체이고, JPA 엔티티는 데이터베이스의 테이블과 1:1로 매핑되는 객체입니다.
Domain Entity
- 비즈니스 로직을 포함
- 식별자를 가짐
- 특정 기술(JPA, Hibernate 등)에 의존하지 않음
JPA Entity
- @Entity
- 비즈니스 로직보다는 데이터 매핑
- 영속성 컨텍스트에 의해 관리
From an architectural point of view, the database is a non-entity—it is a detail that does not rise to the level of an architectural element. Its relationship to the architecture of a software system is rather like the relationship of a doorknob to the architecture of your home.
By. Robert C. Martin
위는 로버트 마틴의 <Clean Architecture>에 기재된 부분입니다. 도메인 엔티티와 JPA 엔티티가 다르고, 이를 분리해야 한다고 명시적으로 말하고 있지는 않지만, 데이터베이스는 엔티티가 아니라고 말하고 있습니다. 이는 ORM 중 하나인 JPA도 포함된다고 이야기 할 수 있습니다.
그럼 이렇게 명확하게 달라보이는데, 왜 많은 관점이 존재하는 걸까요?
Spring Data considers domain types to be entities, more specifically aggregates. So you will see the term "entity" used throughout the documentation that can be interchanged with the term "domain type" or "aggregate".
As you might have noticed in the introduction it already hinted towards domain-driven concepts. We consider domain objects in the sense of DDD. Domain objects have identifiers (otherwise these would be identity-less value objects), and we somehow need to refer to identifiers when working with certain patterns to access data. Referring to identifiers will become more meaningful as we talk about repositories and query methods.
위는 Spring Data JPA 공식문서에서 발췌한 글입니다. 애초에 Spring Data JPA는 도메인 주도 설계를 고려하여 개발된 프레임워크고, 우리가 흔히 사용하는 JpaRepository<T, TID>의 T는 애그리거트 루트 입니다. 줄여서 말하면 JPA는 ORM 기술 중 하나이지만, DDD의 개념이 적용된 기술이라는 것입니다.
왼쪽에서 보면 같아보이고, 오른쪽에서 보면 달라보이면서, 위에서 보면 또 같아보이고, 아래에서 보이면 또 달라보이는 두 개념을 같다고 보고 통합할지, 다르다고 보고 분리할지에 대해 팀 내에서도 이야기를 나누었고, 이 글의 제목에서 알 수 있듯이 JPA 엔티티와 도메인 엔티티를 분리하고 최종 결정하였습니다.
도메인 엔티티 분리하기
DDD와 관련하여 레퍼런스 및 예시 프로젝트를 찾아보면 도메인 엔티티와 JPA 엔티티를 분리하는 경우가 대부분 입니다. 이유는 위에서도 말씀드렸듯이 JPA라는 기술 자체가 DDD 개념이 반영된 기술이고, JPA의 실용적인 기능들을 활용하기 위해 어느 정도의 허용을 한 것인데요, 그럼에도 저희 팀에서 도메인 엔티티와 JPA 엔티티를 따로 분리한 이유는 다음과 같습니다.
- 리팩토링의 주 목적(DDD 적용 주 목적)은 좋은 설계를 위함입니다.
- 추후에 NoSql 등을 도입할 때 유연하게 마이그레이션이 가능합니다.
- 모듈화 및 관심사의 분리에 적합합니다.
간단한 예시로 Center 도메인의 코드를 가지고 와보았습니다. (예시의 코드는 실제 프로덕트의 코드와 상이합니다.)
@Getter
public class Center extends AggregateRoot<Center, CenterId> {
private CenterId id;
private FranchiseId franchiseId;
private Address address;
private Location location;
private CenterStatus centerStatus;
private AuditDomain auditDomain;
@Builder
public Center(
...
) {
...
}
public void update(
...
) {
...
}
public void delete(
...
) {
...
}
}
설계한 도메일 모델을 그 어떤 기술에 대한 의존 없이 그대로 코드로 옮겨놓았습니다. 이 도메인 엔티티로 구성된 Domain 모듈은 POJO(Plain Old Java Object)로만 구성됩니다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity(name = "center")
public class CenterEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "center_id", nullable = false)
private Long id;
@Column(name = "franchise_id", nullable = false)
private Integer franchiseId;
@Column(name = "post_number", nullable = false)
private String postNumber;
@Column(name = "center_address_1", nullable = false)
private String centerAddress1;
@Column(name = "center_address_2", nullable = false)
private String centerAddress2;
@Column(name = "latitude")
private String latitude;
@Column(name = "longitude")
private String longitude;
@Column(name = "center_status", nullable = false)
@Enumerated(EnumType.STRING)
private CenterStatus centerStatus;
@Embedded
private AuditEntity auditEntity;
@Builder
public CenterEntity(
...
) {
...
}
}
JPA 엔티티는 Infrastructure 모듈에 존재하고, 비즈니스 로직을 가지고 있지 않습니다. 그럼 두 엔티티 간의 변환은 어떻게 할까요?
public abstract class BaseMapper<AR, ARE> {
public abstract AR toDomain(ARE entity);
public abstract ARE toEntity(AR domain);
protected AuditDomain toDomain(AuditEntity entity) {
return AuditDomain.builder()
.createdBy(entity.getCreatedId())
.createdDate(entity.getCreatedDate())
.updatedBy(entity.getUpdatedId())
.updatedDate(entity.getUpdatedDate())
.build();
}
protected AuditEntity toEntity(AuditDomain domain) {
AuditEntity entity = new AuditEntity();
entity.setCreatedId(domain.getCreatedBy());
entity.setCreatedDate(domain.getCreatedDate());
entity.setUpdatedId(domain.getUpdatedBy());
entity.setUpdatedDate(domain.getUpdatedDate());
return entity;
}
. . .
}
위는 BaseMapper 추상 클래스 입니다. 도메인 엔티티에서 JPA 엔티티로의 변환과 JPA 엔티티에서 도메인 엔티티로의 변환에 대한 책임을 부여하였습니다. BaseMapper를 상속받는 구현체에서는 @Mapper 어노테이션이라는 커스텀 어노테이션을 만들어 명시적으로 어떤 컴포넌트인지 나타내주고, toDomain()과 toEntity() 추상 메서드를 구현해주었습니다.
public abstract class BaseRepository<AR extends AggregateRoot<AR, ARID>, ARID, ARE, AREID> implements Repository<AR, ARID> {
protected JpaRepository<ARE, AREID> repository;
protected BaseMapper<AR, ARE> mapper;
protected BaseRepository(
JpaRepository<ARE, AREID> repository,
BaseMapper<AR, ARE> mapper
) {
this.repository = repository;
this.mapper = mapper;
}
@Override
public AR save(AR root) {
final ARE entity = repository.save(mapper.toEntity(root));
return mapper.toDomain(entity);
}
@Override
public void delete(AR root) {
repository.delete(mapper.toEntity(root));
}
}
Repository 생성자는 JpaRepository와 BaseMapper를 필수로 받고 있습니다. save()와 delete()에서는 도메인 엔티티를 파라미터로 받고 있기에 Service 레이어에서는 내부 동작뿐 아니라 어떤 ORM을 활용하는지 몰라도 됩니다.
JPA와 이별하기
도메인 엔티티와 JPA 엔티티를 분리하면서 사실상 JPA의 실용적인 기능들과 이별을 하게 되었습니다...⭐️ 리팩토링을 진행하며 여러 이슈를 만났지만, 이번 포스팅에서는 크게 두 가지 이슈와 그 이슈들을 해결하는 과정을 공유하려고 합니다.
더티체킹을 못 쓴다고?
더티체킹을, 더 정확히는 영속성 컨텍스트가 주는 이점들을 모두 활용하지 못하게 되었습니다. JPA를 활용하면 repository.save()를 호출하지 않아도 트랜잭션이 끝나는 시점에 변화가 있는 모든 엔티티 객체를 데이터베이스에 자동으로 반영해주는데요, 비즈니스 로직을 도메인 엔티티가 담고 있기 때문에 더티체킹이 이루지지 않습니다. 그렇다면 update를 어떻게 처리해야 할까요? 다음은 JpaRepository의 구현체인 SimpleJpaRepository의 save 메서드 입니다.
...
@Transactional
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null");
if (this.entityInformation.isNew(entity)) {
this.entityManager.persist(entity);
return entity;
} else {
return this.entityManager.merge(entity);
}
}
...
새로운 JPA 엔티티의 경우에는 persist() 메서드를 호출하고, 이미 존재한다면 merge()를 호출합니다. update 동작이라면 id가 존재하기 때문에 merge()를 호출할 것입니다. merge() 메서드는 준영속 혹은 비영속 상태의 객체를 영속 상태로 변경해주는 역할을 하는데요, 따라서 해결방법은 간단합니다. repository.save()를 명시적으로 호출해주면 됩니다. 다음은 예시 코드 입니다.
public class CenterUpdateService {
...
public void updateCenter(
CenterUpdateCommand cmd
) {
var center = repository.find(CenterId.from(dto.userUseProductId()));
center.update(cmd.address(), cmd.location());
repository.save(center);
}
}
Audit Column cannot be null
영속성 컨텍스트를 떠나보내면서 JPA의 Audit 기능 역시 사용할 수 없게 되었습니다. 내부적으로 merge()를 호출하면서 새로운 영속 엔티티를 생성하기 때문입니다. 따라서 JPA Audit 기능을 과감히 버리고, Audit 기능을 Clean하게 개발하기로 결정했습니다.
Clean하게 Audit 하기
사실 Audit 기능은 도메인보다는 데이터와 더 가까운 녀석입니다. 데이터를 보관하는 스토리지(RDB, MongoDB, Redis 등등)별 활용할 수 있는 라이브러리나 프레임워크가 다를텐데요, 먼저 명시적으로 초기화 해보았습니다.
@Getter
public class AuditDomain extends ValueObject<AuditDomain> {
private String createdBy;
private LocalDateTime createdDate;
private String updatedBy;
private LocalDateTime updatedDate;
@Builder
public AuditDomain(
...
) {
...
}
public static AuditDomain create(
String auditor
) {
return AuditDomain.builder()
.createdBy(auditor)
.createdDate(LocalDateTime.now())
.updatedBy(auditor)
.updatedDate(LocalDateTime.now())
.build();
}
public AuditDomain update(
String updatedBy
) {
return AuditDomain.builder()
.createdBy(this.createdBy)
.createdDate(this.createdDate)
.updatedBy(updatedBy)
.updatedDate(LocalDateTime.now())
.build();
}
}
위 코드는 Audit 관련 데이터를 가지고 있는 클래스 입니다. create() 정적 메서드와 update() 메서드가 구현돼있습니다. 이를 활용하여 Audit 데이터를 초기화 해보았습니다.
@Getter
public class Center extends AggregateRoot<Center, CenterId> {
...
@Builder
public Center(
...
) {
...
this.auditDomain = AuditDomain.create(createdBy);
}
public void update(
...
) {
...
this.auditDomain = this.auditDomain.update(updatedBy);
}
public void delete(
...
) {
...
this.auditDomain = this.auditDomain.update(updatedBy);
}
}
도메인 엔티티의 생성자와 update 관련 메서드에 각각 AuditDomain.create(...)와 auditDomain.update(...)를 호출해주면 됩니다. 생각보다 간단하게 해결됐죠?
하지만 이게 정말 최선일까요? JPA Audit 기능을 활용할 때는 Audit 기능에
대해 신경쓰지 않아도 됐습니다. (오바하면 Audit 기능이 있는지도 잘 모르는)
그런데 위와 같은 방법을 활용한다면 Audit 관련 로직을 새 도메인을 생성하거나
메서드를 작성할 때 계속 신경써줘야 합니다. 더 나아가 비즈니스 로직에 데이터 관련
로직이 추가된다고도 해석되죠. 따라서 AOP를 활용하여 이 문제를 해결해주기로
결정했습니다.
Audit 기능의 관점 분리
먼저 플로우 차트를 그려보았습니다.
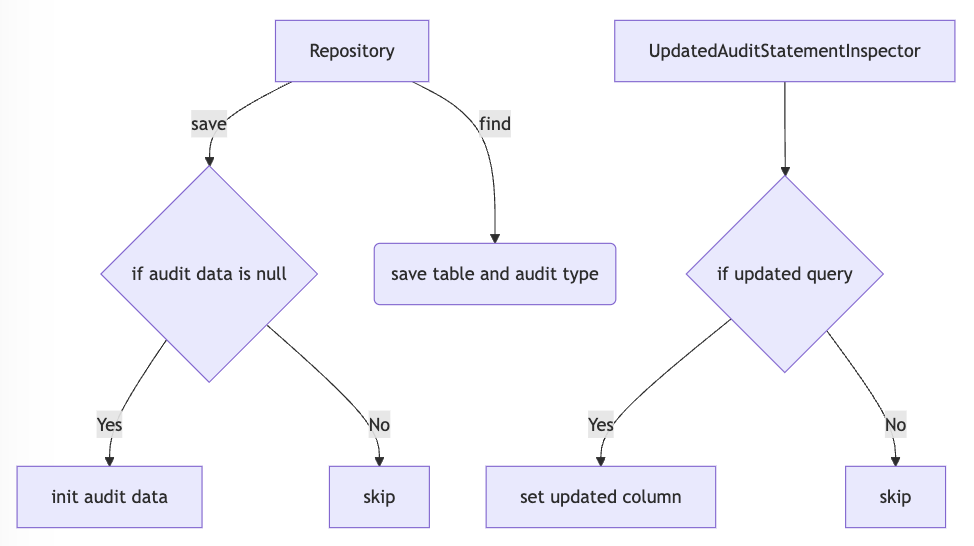
Audit 기능 Flow Chart
플로우 차트만 봐도 어떻게 구현될지 예상이 되시나요? 그럼, 그려둔 플로우 대로 직접 구현하며 설명을 덧붙여보겠습니다.
insert 시점의 Audit
데이터를 추가할 때는 repository.save()가 호출됩니다. 그리고 초기값이기 때문에 당연히 Audit 관련 Column이 모두 null 이죠. 따라서 어드바이스(Advice)를 @Before("execution(* Repository+.save(..))")로 지정해주었습니다. 대략적인 코드는 다음과 같습니다.
@Aspect
@Component
@RequiredArgsConstructor
public class CreatedAuditInitializeAspect {
private final AuditorAware<String> auditorProvider;
private static final String SYSTEM_USER = "SYSTEM";
@Before("execution(* io.assistfit.domain.base.Repository+.save(..))")
public void initAuditValue(JoinPoint joinPoint) throws IllegalAccessException {
Object entity = joinPoint.getArgs()[0];
if (entity == null) {
return;
}
auditUsingBfs(entity);
}
private void auditUsingBfs(Object domain) throws IllegalAccessException {
final Queue<Object> queue = new LinkedList<>();
final Set<Object> visited = new HashSet<>();
queue.offer(domain);
visited.add(domain);
while (!queue.isEmpty()) {
Object current = queue.poll();
var fields = current.getClass().getDeclaredFields();
for (var field : fields) {
field.setAccessible(true);
Object value = field.get(current);
if (isNameField(field, "AuditDomain")) {
initAuditDomain(current, field);
continue;
} else if (isNameField(field, "AuditTimeDomain")) {
initAuditTimeDomain(current, field);
continue;
} else if (isNameField(field, "AuditCreateDomain")) {
initAuditCreateDomain(current, field);
continue;
}
if (value instanceof Collection<?> collection) {
collection.forEach(item -> offerQueue(queue, visited, item));
continue;
}
offerQueue(queue, visited, value);
}
}
}
...
}
Audit 관련 클래스가 세 종류가 있는 만큼, 각 타입에 맞추어 Reflection을 통해 초기화 해주었습니다. 또, 어그리거트 1:N 또는 1:1 관계가 있을 수 있다는 점을 고려하여 bfs 알고리즘을 통해 도메인을 탐색하여 생성되는 모든 도메인 엔티티에 초기화 로직을 적용시켰습니다.
update 시점의 Audit
Update Audit 기능 또한 ORM에 의존하지 않고 AOP와 Reflection을 통해 구현하고 싶었습니다. 하지만 애그리거트에 속한 도메인 엔티티들이 변경사항이 있는지 각각 체크하는 로직이 꽤나 까다롭고, 오버헤드가 크다고 판단되어 다른 방법을 활용하기로 하였고, 그것은 바로 Hibernate의 StatementInspector 입니다.
HibernateProperty로 StatementInspector의 구현체를 등록하면 Query가 실행되는 시점에 Query를 인자로 받는 inspect 메서드가 실행됩니다. 이 Query는 파라미터가 바인딩 되기 전의 Query 입니다. 이 Query가 update문일 때 updated_id=?, updated_date=?를 추가해주면 update 관련 컬럼을 설정해줄 수 있습니다.
이 때, Audit 관련 클래스가 세 종류인 것도 고려해줘야 했습니다. 따라서 TableContext를 통해 각 테이블별 Audit 클래스 타입을 repository.find() 시점에 저장해주었습니다. 해당 로직은 다음과 같습니다.
@Aspect
@Component
public class TableAuditContextInitializeAspect {
@AfterReturning(
pointcut = "execution(* io.assistfit.domain.base.Repository+.find(..))",
returning = "root"
)
public void initializeContext(Object root) throws IllegalAccessException {
if (root == null) {
return;
}
saveTableAuditCache(root);
}
@After("@annotation(org.springframework.transaction.annotation.Transactional)")
public void clearContext() {
TableAuditContextHolder.clearContext();
}
private void saveTableAuditCache(Object domain) throws IllegalAccessException {
final var cache = TableAuditContextHolder.getContext().getCache();
final Queue<Object> queue = new LinkedList<>();
final Set<Object> visited = new HashSet<>();
queue.offer(domain);
visited.add(domain);
while (!queue.isEmpty()) {
Object current = queue.poll();
String simpleName = current.getClass().getSimpleName();
var fields = current.getClass().getDeclaredFields();
for (var field : fields) {
field.setAccessible(true);
Object value = field.get(current);
if (isAuditField(field, "AuditDomain")) {
cache.put(camelToSnake(simpleName), AuditEntity.class);
continue;
} else if (isAuditField(field, "AuditTimeDomain")) {
cache.put(camelToSnake(simpleName), AuditTimeEntity.class);
continue;
} else if (isAuditField(field, "AuditCreateDomain")) {
cache.put(camelToSnake(simpleName), AuditInsertEntity.class);
continue;
}
if (value instanceof Collection<?> collection) {
collection.forEach(item -> offerQueue(queue, visited, item));
continue;
}
offerQueue(queue, visited, value);
}
}
}
...
}
전체적인 로직은 CreatedAuditInitializeAspect의 로직과 비슷한데, @After() 어노테이션이 붙은 하나의 동작이 더 있습니다. 테이블 이름에 대한 Audit 클래스 타입을 담고 있는 TableContext는 ThreadLocal에 저장돼 있는데요, 사용 후 clear()를 해주지 않으면 메모리 누수가 발생할 수 있습니다. 따라서 트랜잭션이 종료될 때 명시적으로 비워주었습니다.
이렇게 저장해둔 Audit 클래스 타입은 StatementInspector의 구현체인 UpdatedAuditStatementInspector에서 update문을 수정할 때 활용됩니다. 다음은 UpdatedAuditStatementInspector 클래스의 코드입니다.
public class UpdatedAuditStatementInspector implements StatementInspector {
private final AuditorAware<String> auditorProvider;
private static final String SYSTEM_USER = "SYSTEM";
private static final int SET_INDEX = 3;
@Override
public String inspect(String sql) {
if (sql.toLowerCase().startsWith("update")) {
final var auditClassType = TableAuditContextHolder.getContext().getCache().get(getTableName(sql));
final int setIndex = sql.toLowerCase().indexOf("set") + SET_INDEX;
final String beforeSet = sql.substring(0, setIndex);
final String afterSet = sql.substring(setIndex);
final StringBuilder sb = new StringBuilder(beforeSet);
setUpdatedColumn(auditClassType, sb);
return sb.append(afterSet).toString();
}
return sql;
}
private String getTableName(String sql) {
return sql.split(" ")[1];
}
private <T> void setUpdatedColumn(
final Class<T> auditClassType,
final StringBuilder sb
) {
if (auditClassType == AuditEntity.class) {
sb.append(setUpdatedId()).append(setUpdatedDate());
} else if (auditClassType == AuditTimeEntity.class) {
sb.append(setUpdatedDate());
}
}
private String setUpdatedId() {
return " updated_id='%s',".formatted(getAuditor());
}
private String setUpdatedDate() {
return " updated_date=current_timestamp,";
}
private String getAuditor() {
return auditorProvider.getCurrentAuditor().orElse(SYSTEM_USER);
}
}
위 코드를 보면 여기서 한 가지 의문점이 들 수 있습니다. update문에 이미 updated 관련 컬럼 설정이 포함돼 있다면 어떻게 될까요? 당연히 SQL 관련 에러가 발생합니다. @DynamicUpdate 어노테이션이 붙어있지 않은 JPA 엔티티는 모든 컬럼을 포함한 update문을 미리 생성 및 캐싱해두었다가 update를 발생하면 캐싱해둔 update문을 활용하기에 SQL 관련 에러가 필연적으로 발생합니다. 그렇다고 모든 JPA 엔티티에 @DynamicUpdate 어노테이션을 붙이는건 해결보다는 회피에 가까워 보입니다.
해당 문제는 생각보다 간단하게 해결됩니다. @Column 어노테이션의 updatable 속성을 updatable = false로 설정하여 해당 필드에 대한 updata 쿼리 생성을 막을 수 있습니다.
@Setter
@Getter
@Embeddable
public class AuditEntity {
@Column(name = "created_id", updatable = false, nullable = false, length = 20)
private String createdId;
@DateTimeFormat(iso = DATE_TIME)
@Column(name = "created_date", updatable = false, nullable = false)
private LocalDateTime createdDate;
@Column(name = "updated_id", updatable = false, nullable = false, length = 20)
private String updatedId;
@DateTimeFormat(iso = DATE_TIME)
@Column(name = "updated_date", updatable = false, nullable = false)
private LocalDateTime updatedDate;
}
마치며
이번 글에서는 Clean DDD를 적용하면서 JPA와 이별한 이야기를 담아보았습니다. 처음에는 JPA의 영속성 컨텍스트를 사용하지 못하면서 'JPA를 활용할 때 정말 편리했구나'라는 생각이 들었지만, 이슈들을 해결해 나가면서 뿌듯함(?)을 느낄 수 있었습니다.
JPA 엔티티와 도메인 엔티티를 분리하는 쪽, 통합하는 쪽 모두 트레이드 오프를 가지고 있습니다. 그 중 저희 팀은 ORM이 주는 편리함보다는 도메인 모델을 더 깨끗하게 유지하는 것이 장기적으로 더 좋은 선택이 될 수 있을 것이라 판단하였습니다. 하지만 둘 중 어느 쪽도 정답은 아니기에 프로젝트의 규모와 성격, 구성원의 의견 등을 통해 판단하여 결정하시면 됩니다.
긴 글 읽어주셔서 감사합니다 🙂